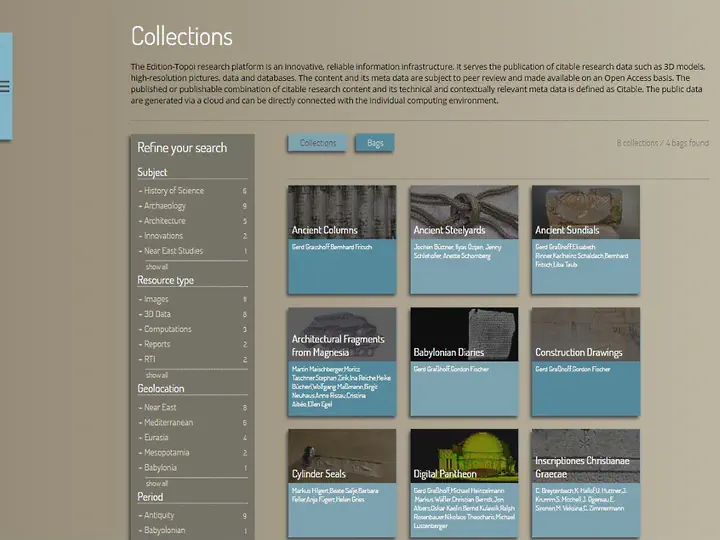
Abstract
Online publishing of almost every type of 3D data has become a quasi-standard routine. Nevertheless, the integration in a web page of a single 3D model, or of a predefined restricted set of models, raises different issues compared to an efficient and effective integration of thousands of them in an online repository. In this case it is mandatory to have an automatized pipeline to prepare and homogenize the dataset. The pipeline should be able to automatically wrap 3D data in all conditions, and display every single model with the best scene setup without any (or with a minimal) interaction by the database maintainers. This paper, retracing the steps of a recent real application case, aims at showing all the faced issues (and the adopted solutions) to publish a large and heterogeneous three-dimensional dataset in a web specialized repository. We want to introduce a valid and reusable strategy, starting from the description of the pipeline adopted for data pre-processing and moving to the choices made in the 3D viewer implementation. The paper concludes with a discussion on the actual state of the integration of 3D data with the other multimedia informative layers.